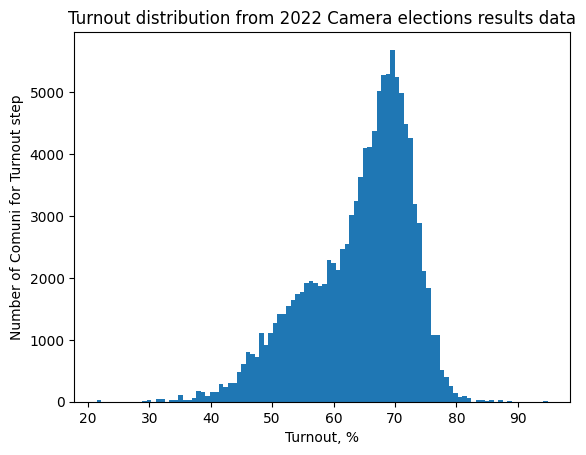
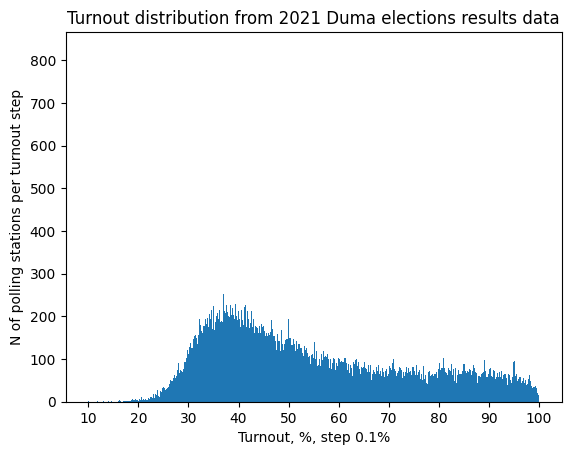
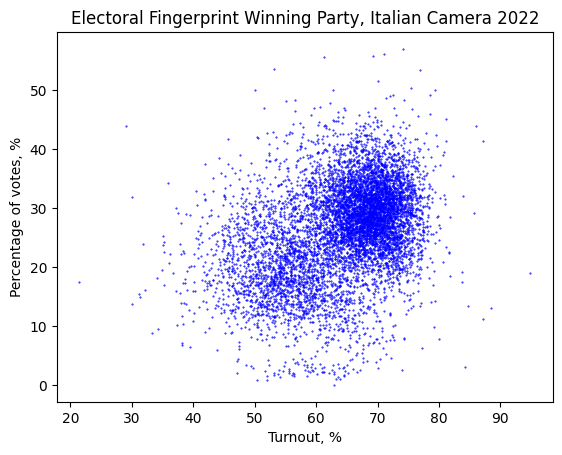
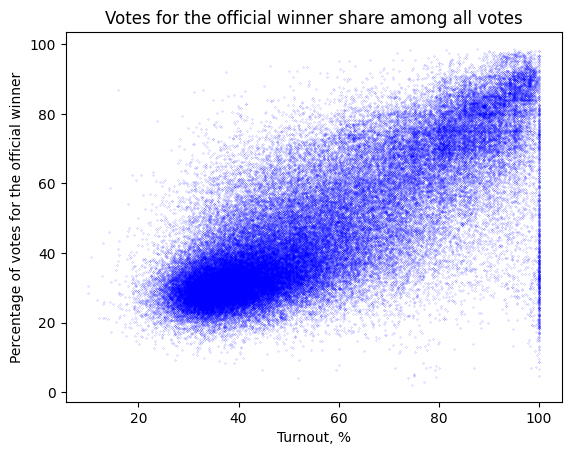
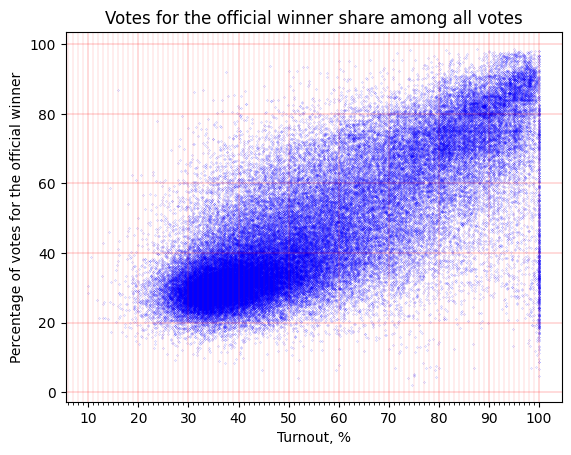
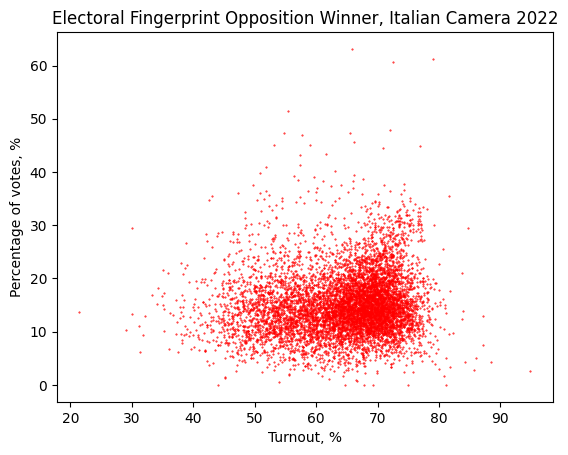
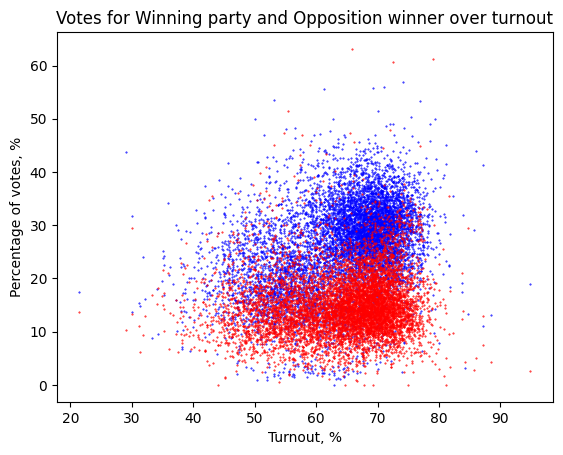
To achieve our objectives, we collect and analyze electoral data with the finest granularity available.
For Italy, we found data at the “comune” (roughly translated as municipality) level (~94,000 entities) on official websites, resulting in a dataset with (~117,594 rows) for Camera dei deputati and (~117,611 rows) for Senato, which makes a few thousand rows for each commune.
For Russia, we accessed data at two levels:
Polling Stations (УИК): This level (~94,000 entities) represents the finest granularity available, where data includes votes for political parties such as КПРФ (Communist Party) and ЕР (United Russia), as well as voter turnout and total registered voters. Additionally, geographic coordinates (latitude and longitude) for each polling station enable spatial analysis.
Territorial Commissions: This aggregated level (~3,000 entities) provides summaries of election results across groups of polling stations.
The Russian dataset was obtained from Sergey Shpilkin, who scraped and preprocessed the data from the official ЦИК website. While ЦИК provides only HTML tables, the processed CSV format allows for easier integration into our analysis.
For consistency and comparability, we primarily focus on the municipality level of granularity where applicable, using polling stations (УИК) as a counterpart to communes in Italy.
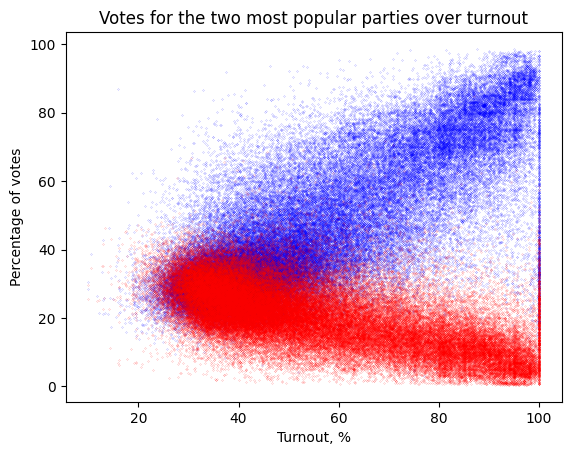
Our analysis involves a comprehensive examination of the data to identify anomalies and potential manipulations. We employ statistical methods and data visualization techniques to illustrate our findings. This approach allows us to demonstrate the strengths and limitations of open data in uncovering electoral fraud and promoting transparency.
By the end of this project, we aim to provide a clear understanding of the role of open data in electoral processes, highlighting both its potential and its limitations. This understanding is crucial for developing strategies to enhance transparency and integrity in elections worldwide.
Italy Dataset Overview
Data Source:
The dataset for the latest Italian parliamentary election (2022) was obtained from the Official Italian Government Election website, accessible at https://elezioni.interno.gov.it/. It is not clear if it’s more related to the Ministry of the Intern (Ministero dell’Interno) or to the government itself.
Granularity:
From a geographical point of view the data is provided at the commune level. The current format presents a challenge as each commune has multiple rows, with each row representing a different candidate. To facilitate analysis, the data needs to be reformatted such that each row corresponds to one commune's electoral results.
Data Format:
The available data is provided in spreadsheet format (csv), which has been converted into .txt files for further analysis.
Columns Description:
- "DATAELEZIONE" - Date of the election
- "CODTIPOELEZIONE" - Election type code (C for Camera, S for Senato)
- "CIRC-REG" - Regional electoral district
- "COLLPLURI" - Collegio Plurinominale
- "COLLUNINOM" - Colleggio Uninominale
- "COMUNE" - Comune name
- "ELETTORITOT" - Total electorate
- "ELETTORIM" - Male electorate (you can of course infer the Female votants with a simple operation but we found it somehow biased)
- "VOTANTITOT" - Total votes cast
- "VOTANTIM" - Male votes cast
- "SKBIANCHE" - Blank votes
- "VOTILISTA" - Party votes
- "DESCRLISTA" - Party name
- "COGNOME" - Candidate's last name
- "NOME" - Candidate's first name
- "LUOGONASCITA" - Candidate’s place of birth
- "DATANASCITA" - Candidate’s date of birth
- "SESSO" - Candidate’s Sex (described as a binary variable, in some context can be considered not politically correct)
- "VOTICANDIDATO" - Candidate votes’
File Structure:
Separate folders are provided for Senate and Camera voting. Notably, in the Camera folder, files include:
- Camera_VAosta_livComune_Scrutini.txt
- Camera_VAosta_LivComune.txt
- Camera_Italia_LivComune.txt
Similarly, in the Senate folder, additional files include:
- Senato_VAosta&Trentino_livComune_Scrutini.txt
- Senato_VAosta&Trentino_LivComune.txt
- Senato_Italia_LivComune.txt
These distinctions might be due to the unique administrative divisions of Valle d'Aosta or some peculiar way of collecting the data they had that made this necessary.
Russia Dataset Overview
Russia Dataset Overview
Data Source:
The dataset for the latest Russian parliamentary elections (Duma elections) was derived from data scraped by Sergey Shpilkin, a well-known electoral statistician, from the official ЦИК (Central Election Commission) website. While the official data is provided only in HTML table format, Shpilkin’s preprocessing converted it into CSV files suitable for analysis.
Granularity:
The data is available at two levels:
Polling Station Level (УИК): Representing approximately 94,000 entities, this is the most granular level. Each row corresponds to a single polling station, capturing detailed election metrics such as voter turnout, total registered voters, and votes for individual political parties.
Territorial Commission Level: An aggregated view of election data summarized across ~3,000 territorial commissions, grouping multiple polling stations into larger administrative units.
Data Format:
The dataset is provided in CSV format, which has been processed to facilitate statistical analysis and visualization.
Columns Description:
- "REGION" - Name of the administrative region (e.g., Moscow, Saint Petersburg).
- "TERRITORY" - Name of the territorial commission.
- "UIK_ID" - Unique identifier for the polling station (УИК).
- "REGISTERED_VOTERS" - Total number of registered voters at the polling station.
- "TURNOUT" - Total voter turnout at the polling station.
- "BLANK_VOTES" - Number of blank votes submitted.
- "INVALID_VOTES" - Number of invalid or spoiled votes.
- "PARTY_A_VOTES" - Votes for Political Party A (e.g., United Russia).
- "PARTY_B_VOTES" - Votes for Political Party B (e.g., Communist Party).
- "OTHER_PARTY_VOTES" - Combined votes for all other parties.
File Structure:
The dataset is organized into a single CSV file containing polling station-level data. Territorial commission data is summarized within the same file, using aggregation methods.
Notable preprocessing steps include:
Normalization: Ensuring uniformity in naming conventions for regions and territories.
Data Cleaning: Addressing inconsistencies such as missing values or duplicate entries.
Derived Columns: Adding calculated metrics such as turnout percentage and vote shares for individual parties.
The dataset’s structure and granularity allow for robust statistical analysis, including spatial visualization and anomaly detection. By incorporating both polling station and territorial commission levels, we can compare trends across different administrative hierarchies.
Data Source:
The dataset pertains to the latest Russian parliamentary elections (Duma elections). While the data is theoretically accessible from the Official Russian Government Election website, it poses challenges for comprehensive extraction due to website formatting issues and captchas blocking data parsers.
Complications in Data Retrieval:
- The data is stored in separate HTML tables for each polling station or 'municipal aggregation'/'territorial commission' of polling stations.
- Captchas and minor formatting techniques hinder automated data parsing efforts.
- Original websites accessible only from Russian IP addresses
Data Collection Method:
To overcome the challenges related to the data collection, we utilized datasets preprocessed and scraped by Sergey Shpilkin, a prominent electoral statistician known for his work in identifying anomalies in Russian elections. Shpilkin's processed CSV files offer a structured and cleaned version of the data, enabling detailed analysis without the technical hurdles associated with direct data extraction from the ЦИК website.
Dataset Composition:
The dataset consists of multiple .csv files:
- Polling Station Level Data: Granularity at the level of individual polling stations.
- Territorial Commission Level Data: Aggregated data covering several polling stations within a 'territorial commission,' roughly equivalent to a municipality.
- Regional Level Data: Data aggregated at the regional level.
- Remote Voting Data: Data pertaining to remote voting, where votes were registered online rather than on paper ballots.
Focus and Analysis:
The primary focus is on the second file (Territorial Commission Level Data) to maintain consistency with the granularity of the Italian dataset. However, a closer examination of the first file (Polling Station Level Data) may be necessary to detect specific anomalies or irregularities.
Back to the Top ↑